
Prerequisites
Install the following packages using the command prompt in your IDE
Tweepy (for accessing the Twitter API)
pip install tweepyNLTK (for natural language processing)
pip install nltk
Python-Dotenv (for managing environment variables)
pip install python-dotenv
Matplotlib (for data visualization)
pip install matplotlibDownload and store the emotions.txt file on the project directory.
'victimized': 'cheated', 'accused': 'cheated', 'acquitted': 'singled out', 'adorable': 'loved', 'adored': 'loved', 'affected': 'attracted', 'afflicted': 'sad', 'aghast': 'fearful', 'agog': 'attracted', 'agonized': 'sad', 'alarmed': 'fearful', 'amused': 'happy', 'angry': 'angry', 'anguished': 'sad', 'animated': 'happy', '...Step 1: Setting Up the Environment
Code Snippet
from dotenv import load_dotenv import os # Load environment variables load_dotenv()
# Set up API keys consumer_key = os.getenv("CONSUMER_KEY")
consumer_secret = os.getenv("CONSUMER_SECRET")
access_token = os.getenv("ACCESS_TOKEN")
access_token_secret = os.getenv("ACCESS_TOKEN_SECRET")
bearer_token = os.getenv("BEARER_TOKEN")Explanation
dotenv:- The
dotenvmain rule is to load environment variables (variables that hold API keys) from the.envfile. - These variables are stored securely and privitaly outside the code in order to protect sensitive information such as API keys, it is also useful when using version control platforms such as GitHub, such platforms it allows you to ignore specific files from being added by adding them to the .gitignore file on GitHub or a similar platform, version control platform aren’t safe even if a project has been made private.
- The
os.getenv():- This function is used to get the value of an environment variable (e.g. an API key) by name.
- Example:
os.getenv("CONSUMER_KEY")fetches theCONSUMER_KEYfrom the.envfile.
- Purpose:
- This whole process will keep important credentials secure and prevent them from being hardcoded in the script.
Step 2: Fetching Tweets To Be Analysed By Our Tool
Code Snippet
import tweepy
# Initialize the client client = tweepy.Client( bearer_token=bearer_token, consumer_key=consumer_key, consumer_secret=consumer_secret, access_token=access_token, access_token_secret=access_token_secret, wait_on_rate_limit=True ) # Define search query search_query = "about birds lang:en" try: # Search for tweets tweets = client.search_recent_tweets( query=search_query, max_results=100, tweet_fields=['created_at', 'author_id'] ) if tweets.data: # Save tweets to file with open("tweets.txt", "w", encoding='utf-8') as file: for tweet in tweets.data: file.write(tweet.text + '\n') # Print success message print(f"Successfully saved {len(tweets.data)} tweets to tweets.txt") else: # Print error message if no tweets found print("No tweets found.") except tweepy.TweepyException as e: # Print error message if Twitter API exception occurs print(f"Twitter API Error: {str(e)}") Explanation
Initialize the Twitter Client:
- The
tweepy.Clientobject is initialized with the APIs you normally get when registering as an X Developer, that will allow us to retreave tweets into our application. - The parameter
wait_on_rate_limit=Truewill make sure the script stops when it reaches the specified rate limit.
- The
Search for Tweets:
search_recent_tweetsloads tweets using the search query which is ("about birds").max_results=100sets the value of the max number of tweets that we should load, this is important as our basic X Developer account doesn’t allow us to retreave more than 1500 tweets per month (maximum allowed is 100 per request).tweet_fieldsrequests additional metadata, such ascreated_atandauthor_idwhich can be beneficial to some.
Save Tweets to a File:
- The tweets’ text outputs are saved in the
tweets.txtfile, allowing us to perform Sentiment Analysis on them.
- The tweets’ text outputs are saved in the
Error Handling:
- If there is an API error, the exception (
TweepyException) is caught, and an error message is displayed.
- If there is an API error, the exception (
Step 3: Preprocessing Text
Code Snippet
import string from collections import Counter import matplotlib.pyplot as plt # Read tweets from file text = open("tweets.txt", encoding="utf-8").read()
# Convert to lowercase lower_case = text.lower()
# Remove punctuation clean_text = lower_case.translate(
str.maketrans('', '', string.punctuation)
)
# Tokenize words tokenized_words = clean_text.split()
# Define stop words stop_words = [
"i", "me", "my", "myself",
"we", "our", "ours", "ourselves",
"you", "your", "yours", "yourself",
"yourselves", "he", "him", "his",
"himself", "she", "her", "hers",
"herself", "it", "its", "itself",
"they", "them", "their", "theirs",
"themselves", "what", "which", "who",
"whom", "this", "that", "these",
"those", "am", "is", "are",
"was", "were", "be", "been",
"being", "have", "has", "had",
"having", "do", "does", "did",
"doing", "a", "an", "the",
"and", "but", "if", "or",
"because", "as", "until", "while",
"of", "at", "by", "for",
"with", "about", "against", "between",
"into", "through", "during", "before",
"after", "above", "below", "to",
"from", "up", "down", "in",
"out", "on", "off", "over",
"under", "again", "further", "then",
"once", "here", "there", "when",
"where", "why", "how", "all",
"any", "both", "each", "few",
"more", "most", "other", "some",
"such", "no", "nor", "not",
"only", "own", "same", "so",
"than", "too", "very", "s",
"t", "can", "will", "just",
"don", "should", "now"
]
# Remove stop words final_words = [word for word in tokenized_words if word not in stop_words]
Explanation
Text Input:
- First we will read all the loaded tweets which were stored in
tweets.txt.
- First we will read all the loaded tweets which were stored in
Convert to Lowercase:
- We will convert all the characters on the tweets to lowercase using the function
.lower(). - This is used to standardizes the text making it easier to process.
- We will convert all the characters on the tweets to lowercase using the function
Remove Punctuation:
str.maketrans('', '', string.punctuation)this creates a translation table to remove punctuation from all the tweets.
Tokenization:
- Splits the cleaned text into individual words and then storing them on an array using the function
.split().
- Splits the cleaned text into individual words and then storing them on an array using the function
Stop Words:
- Stop words are common words that has no emotions and adds no emotions to be analysed by our program for example (like “and,” “the,” “is”).
- This step removes these words from
tokenized_words.
Step 4: Mapping Emotions
Code Snippet
from collections import Counter # Map words to emotions emotion_list = [] with open("emotions.txt", "r") as file: for line in file: clear_line = line.strip().replace("'", "").replace(",", "") word, emotion = clear_line.split(":")
if word in final_words: emotion_list.append(emotion) # Count emotions emotion_count = Counter(emotion_list) print(emotion_count)
Explanation
Open
emotions.txt:- Read the
emotions.txtfile which contains the word-to-emotion mappings ( for example “happy:joy”).
- Read the
Cleaning the Lines:
- Each line is stripped of extra characters using the method (
strip()which is used to remove any leading, and trailing whitespaces) and formatted to ensure the words are processed accuratly.
- Each line is stripped of extra characters using the method (
Word Matching:
- If a word from
final_wordsexists on the mapping file, its associated emotion is appended toemotion_list.
- If a word from
Emotion Count:
- The
Counterobject counts how frequent do each emotion occur.
- The
Step 5: Sentiment Analysis using NLTK
Code Snippet
from nltk.sentiment.vader import SentimentIntensityAnalyzer # Perform Sentiment Analysis sia = SentimentIntensityAnalyzer() sentiment = sia.polarity_scores(clean_text) print('Sentiment Analysis:', sentiment)
Explanation
SentimentIntensityAnalyzer:
- Part of NLTK’s
VADERtool, designed for sentiment analysis of text data.
- Part of NLTK’s
Polarity Scores:
- The
polarity_scoresmethod returns:neg: Negative sentiment proportion.neu: Neutral sentiment proportion.pos: Positive sentiment proportion.compound: Overall sentiment score (from: -1 to 1).
- The
Example Output:
# Print sentiment analysis result print('Sentiment Analysis:', sentiment)
Step 6: Visualizing Results
Code Snippet
# Plot emotions fig, ax1 = plt.subplots()
ax1.bar(emotion_count.keys(), emotion_count.values())
fig.autofmt_xdate()
plt.savefig("emotions.png")
plt.show()
Explanation
Create Bar Chart:
plt.bar()creates a bar graph with the axis:- X-axis: Emotions.
- Y-axis: Emotion counts.
Format the X-axis:
fig.autofmt_xdate()makes the graph more readable by adjusting the labels.
Save and Display the Plot:
- Saving the graph as
emotions.pngand display it usingplt.show().
- Saving the graph as
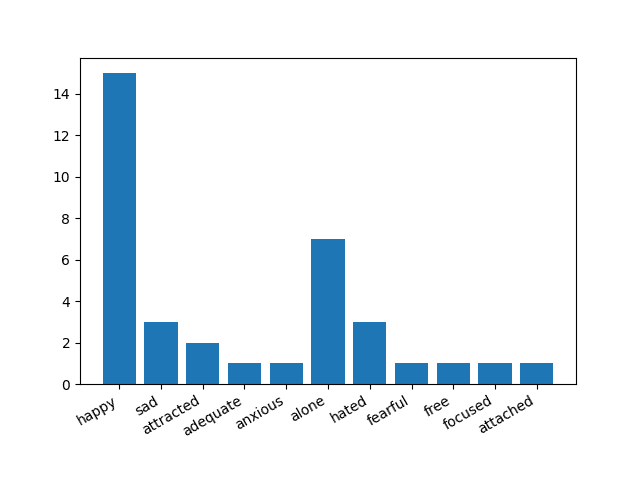
Example Result of a Sentiment Analysis performed in a Speech by Mark Zuckerberg
Live Demo - Getting Tweets using X Developer API & Sentiment Analysis using NLTK
Sources used:
- I have learned Sentiment Analysis using Python from the following playlist on youtube: Playlist
- I have learned Tweepy from different online sources including github to install the package itself.
